
New Delhi: Microsoft has introduced a fresh update to its AI research workflow inside Microsoft 365 Copilot, pushing deeper into multi-model systems. The company is now rolling out two new capabilities called Critique and Council, aimed at improving how AI handles complex research tasks inside workplaces.
Microsoft says the new system moves away from single-model workflows and instead brings multiple AI models into one pipeline. This change, according to the company, is meant to improve how research is generated, reviewed, and presented.
Introducing Critique, a new multi-model deep research system in M365 Copilot.
You can use multiple models together to generate optimal responses and reports. pic.twitter.com/m4RlQmCKzs
— Satya Nadella (@satyanadella) March 30, 2026
What Microsoft Critique does inside Copilot
Critique is designed as a two-part AI system. One model creates the research output, and another model reviews it. It sounds simple on paper, but the way it works is quite layered.
Microsoft explains, saying, “It separates generation from evaluation and utilizes a combination of models from Frontier labs including Anthropic and OpenAI.”
In practice, the first model plans the task, gathers information, and produces a draft. Then a second model steps in as a reviewer. This reviewer checks the draft carefully, improves the structure, strengthens the arguments, and fixes weak points before the final version is ready.
The company says this reviewer follows a structured method called rubric-based evaluation. It focuses on checking if the sources are reliable, whether the report covers all important points, and if every major claim is backed by proper evidence.
“By giving evaluation as much emphasis as generation, this architecture creates a powerful feedback loop.”
From a real-world lens, this feels familiar. In newsrooms, no story goes out without an editor reading it. That second layer often changes everything.
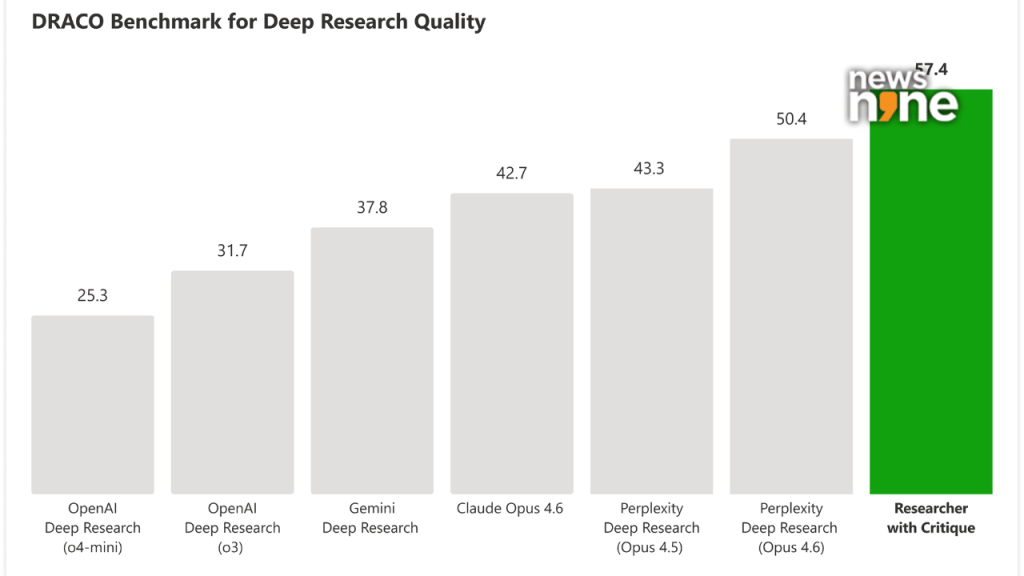
Draco Benchmark: Source Microsoft
DRACO benchmark shows gains
Microsoft tested Critique using the DRACO benchmark, which includes 100 complex research tasks across different domains.
The results show gains in how the system performs. The company reports better depth in analysis, stronger presentation quality, and improved factual accuracy compared to earlier single-model systems. It claims an overall improvement of about 13.88 percent over competing systems.
Microsoft also said, “Critique pushes Researcher to identify missing analytical angles, close coverage gaps, sharpen formulations.”
That sounds very close to what human editors do every day. They spot gaps, question weak claims, and push for clarity.
New in M365 Copilot: Council.
You can run multiple models on the same prompt at the same time, so you can see where they align and diverge, and understand what each adds. pic.twitter.com/2p7O14OLFp
— Satya Nadella (@satyanadella) March 30, 2026
What Council brings to the table
Council takes a different approach. Instead of one model reviewing another, it runs multiple AI models at the same time.
Microsoft describes it like this. “Council runs an Anthropic and OpenAI model simultaneously, with each model producing a complete, standalone report.”
Each model creates its own version of the research. After that, a separate judge model steps in. This judge compares both reports, looks at where they agree, where they differ, and then creates a final summary that highlights key findings and differences in interpretation.
This feels like asking two experts the same question and then comparing their answers before making a decision. It is something many journalists and analysts already do when covering complex topics.
Why this matters
Microsoft is moving toward multi-model AI systems where different models handle different roles. One writes, another reviews, and sometimes a third compares.
Critique focuses on improving depth and accuracy within a single workflow. Council focuses on bringing multiple viewpoints together. Both approaches show that AI systems are slowly moving beyond just answering queries. They are starting to handle reasoning in a more structured and layered way.