
New Delhi: Sarvam AI is making a fresh play for India’s messy, real-world speech, where people jump between languages mid-sentence and talk over traffic noise. The Bengaluru startup said its new speech recognition model, Saaras V3, expands coverage to all 22 scheduled Indian languages, plus English.
If you have ever tried voice typing on a loud street or during a bad call, you know the pain. Dictating a simple address once and watching the phone confidently type something that looked like a different planet. Sarvam is pitching Saaras V3 as a fix for that kind of everyday chaos.
Drop 8/14: Introducing Saaras V3, the next iteration of our speech recognition model. We extend our lead in this space with an even more accurate model, particularly for mixed-language and noisy speech.
We have also expanded support for all the 22 scheduled languages of India.…— Pratyush Kumar (@pratykumar) February 11, 2026
Saaras V3 adds 22-language coverage and real-time streaming
Sarvam says Saaras V3 is built on a new architecture and now supports streaming speech recognition, so it can start producing text as audio is still coming in. The company framed it as a speed and usability upgrade, saying the goal is faster “time to first token” and smoother live transcription.
In its blog, Sarvam opened with a line that sets the tone for the India-focused pitch: “India runs on voice. Billions of them. Today, we’re introducing Saaras V3, built to understand all of them.”
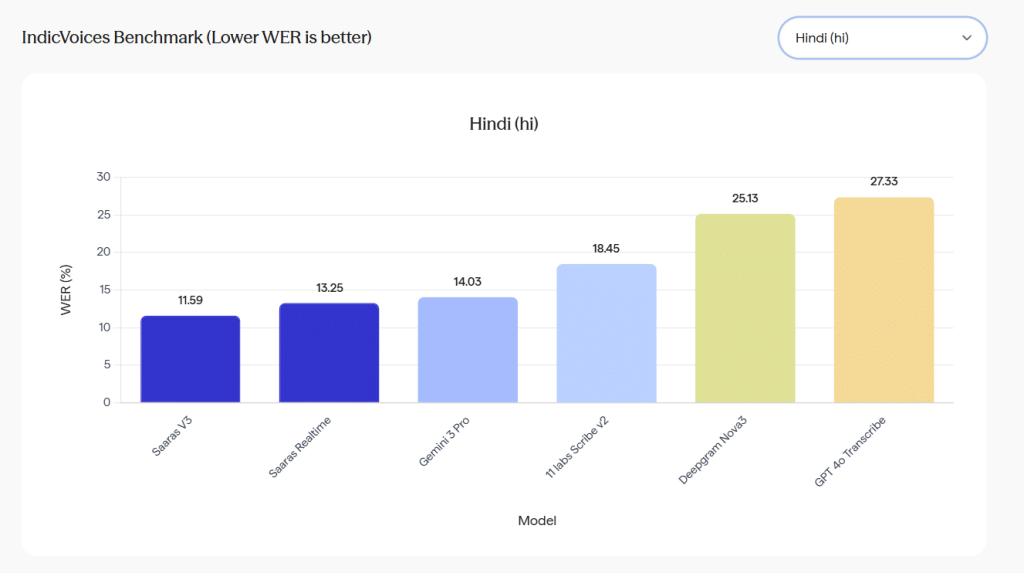
IndicVoices Benchmark (Lower WER is better) | Source: Sarvam AI
Benchmark claims: Lower word error rate on IndicVoices and Svarah
Sarvam is also leaning hard on benchmark results. The company says Saaras V2.5 hit about 22 percent word error rate on the IndicVoices benchmark. With Saaras V3, it says the word error rate drops to about 19 percent on the same dataset.
On the subset of the 10 most popular languages within IndicVoices, Sarvam reports Saaras V3 at about 19.31 percent WER. The startup also claims the gap grows on the remaining 12 languages, which include lower-resource Indian languages where many global systems either do not support the language or show weaker results.
Sarvam’s co-founder Pratyush Kumar shared charts on X comparing Saaras V3 against other systems on IndicVoices and Svarah.
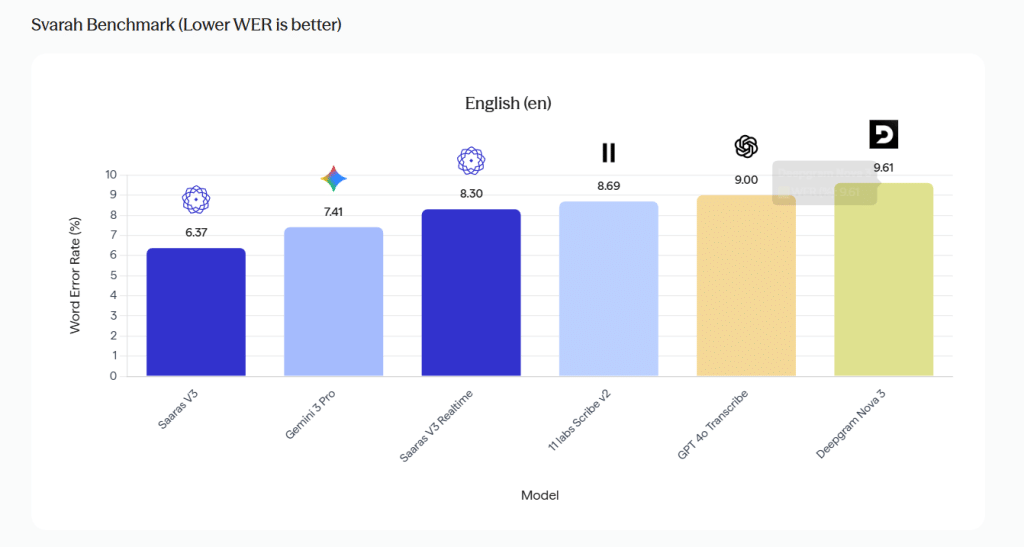
Svarah Benchmark (Lower WER is better) | Sarvam AI
Training scale and the kind of speech it targets
Sarvam says Saaras V3 was trained on 1 million plus hours of curated multilingual audio, covering Indian languages, accents, and real recording conditions. The blog also says the model was tuned for things that usually break speech systems in India:
- Code-mixed talk, like Hindi mixed with Bengali or English
- Noisy speech, like calls, streets, and crowded rooms
- Named entities and numbers, like dates, prices, and IDs
Why this matters for products people actually use
Sarvam says streaming speech recognition is aimed at use cases where waiting is not an option. It listed scenarios like live captions, voice assistants, gaming interactions, call-centre assist tools, and real-time transcription.
The model also claims support for features that teams keep asking for in production work, not just clean transcripts. Sarvam says Saaras V3 supports automatic language detection, word-level timestamps, output formatting control, and speaker diarisation for multi-speaker conversations.
Sarvam AI is part of the IndiaAI mission startup cohort, and it is positioning its models around Indian languages and local data formats instead of a one-size chatbot pitch.